과제에 대해 간략히 설명하자면, 필자가 국내 4대 정유업 중 한 곳에서 2020년도 2월~10월까지 약 10개월간 수행한 몇 가지 AI 과제 중 하나이며, 여러 저유소의 여러 유종들의 미래 30일 출하량을 예측하는 모델을 구축하였다.
프로젝트 과정과 그 중간의 이슈사항 등을 하나부터 열까지 설명하면 끝도 없이 길어 지기 때 분에 생략하고, 핵심과정과 기술만 간략하게 리뷰한다.
AI과제는 크게 3가지를 수행하였고, 출하 예측모델/재고 최적화/이관 최적화를 수행하였다. 어쩌다 보니 3가지를 다하게 되었는데, 이를 본 페이지에서 설명하기엔 내용이 산으로 가기 때문에, 기회가 되면 다음에 별개의 페이지에서 서술해보겠다.
일단, 모델 구축에 있어 어려움을 설명하자면, 정유업에서 저유소의 출하량 데이터는 해당 정유업의 전략과 재고 부족, 비정기적 이벤트성 등에 의한 노이즈가 큰 데이터이며, 이러한 노이즈를 설명할 수 있는 데이터가 전부 존재하진 않았다. 또한, 이로 인해 타깃 데이터의 fluctuation 더 커지는 현상이 있었다. 게다가 2020년에는 코로나 이슈로 인하여 그 출하량에 이벤트성 노이즈가 굉장히 컸기 때문에, 결과를 검증하기에 어려웠다. 다만, 노이즈를 보정할 수 있는 정보가 일부(한 20~30% 정도 될까?) 존재하였고, 출하량 데이터는 시계열성이 비교적 큰 데이터였기 때문에 시계열 모델을 구축하기엔 나쁘지 않았다.
데이터의 경우 출하량 데이터는 2015년부터 2020년까지 약 6~7년가량의 daily 데이터가 존재(그래 봤자 약 2000개밖에 안된다)하고, 그 외 내부정보(비밀~) 및 외부정보(날씨, 유가, 날짜, 공휴일, 기타 공공데이터 등등)를 사용하였다.
이러한 데이터들의 경우 기본적인 Feature engineering작업을 진행해주었고, 몇 가지 서술하자면, 파생변수 생성, feature selection, scaling, feature transform(데이터 특징에 맞게 변환), 변수 인코딩 등등을 진행하였다. 상기한 Feature engineering 작업은 비즈니스 및 EDA를 통한 충분한 데이터에 대한 이해를 기반으로, 변수 특징에 맞는 적절한 작업을 진행하였다.
예를 들어 월 변수(1월~12월)의 경우 시계열에서 굉장히 중요한 변수이며, 이러한 변수는 그대로 넣으면 모델이 학습하기 굉장히 어렵다. 따라서 일반적으론 one-hot인코딩을 진행하나, 변수가 늘어나는 단점이 존재한다. 따라서 필자는 해당 변수를 계절성을 반영하는 변수로 판단하였고, 해당 변수에 cos변환을 주어서 겨울에는 높은 값(최대 1)을 가지고, 여름에는 낮은 값(-1)을 가지도록 설계하였다.(당연히 봄가을에는 0에 가까운 값을 가진다)
모델의 구축방향은 크게 3가지성격의 회귀모형/분배 모델/딥러닝 모델을 구축하였다. 여기서 필자는 딥러닝 모델을 구축하였으므로, 나머지 모델에 대한 설명은 생략한다.
해당 데이터와 주제에 맞는 여러 알고리즘을 탐색 및 프로토타이핑을 진행하였고(CNN, RNN계열, Transformer 등등), 그중 모델 복잡성 대비 준수한 성능을 보인 GRU를 메인으로 가지는 모델을 구축하였다.
해당 과제에서 서버에 GPU를 안 사줬다...... CPU로 돌아가는 딥러닝 모델을 만들어야 했기 때문에, 무거운 모델을 돌리고 싶어도 돌릴 수가 없었다......
미래 30일의 일별 출하량을 예측하기 위해서 시계열성을 볼 필요가 있었고, 과연 며칠까지 시계열성을 보는 것이 좋은지에 대한 이슈가 있었다. seq2seq모델의 단점 중 하나로, 너무 긴 시퀀스는 기울기 소실(Gradient vanishing)이 발생할 것이고(이를 최소하 하기 위한 여러 가지 기법(Activation function, Gradient Clipping, Weight initialization, Normalization, etc)들이 있지만, 완벽하게 해결했다고 보긴 힘들다), 중요 시점의 정보가 제대로 학습되지 않을 수 있다. 따라서 적절한 기간을 찾을 필요가 있었고, 360~1일까지 조절해가면서 속도 대비 좋은 성능을 보여주는 기간을 찾았다. 그 결과, 미래 30일의 일별 출하량을 예측하는데 5일(비교적 적은 기간임에도 가장 우수한 성능을 보였다. 단, 모델의 복잡도가 다소 심플해서 긴 기간이 제대로 학습이 안 되었을 수도 있다)만 보아도 충분한 성능을 보였다.
최종적으로 69개의 속성들을 가지고 과거 5일의 정보를 학습하여 미래 30일의 출하량을 예측하는 Simple GRU모델을 구축하였고, 그 구조는 다음과 같다.

그 결과 예측 시기와 저유소에 따라 다르지만 평균적으로 30일 평균 MAPE가 30 정도의 성능을 보였다.
여기서 MAPE를 성능 측정지표로 사용하고 있는데, 아는 사람은 알겠지만, MAPE는 문제가 많은 측정지표이다. 따라서 시계열 모델에서 MAPE는 잘 사용하지 않는 지표인데, 유일한 장점으로 비 전공자들이 다른 측정지표에 비해 직관적으로 이해하기 쉽다는 이유 많으로(MAPE가 시계열 모델의 정확한 성능을 측정하지 못하는데, 이걸로 모델의 성능을 판단하는 게 무슨 의미가 있다고--;;), 성능 측정지표를 MAPE로 사용하라는 요구 아닌 강요를 받아서, 어쩔 수 없이 본 과제에서 MAPE를 사용하였다. MAPE의 문제점은 따로 글을 작성하도록 하겠다.
추가적으로, 딥러닝 모델의 특성상 초기값에 따른 성능의 편차가 커서(즉, 전역해(Global Minimum)가 아닌 지역해(Local Minimum)를 의미. 또한, seed 고정을 찾아보았는데, 이상하게 고정이 안되었다) 일관성 있는 결과를 도출하기 위하여 같은 조건으로 모델을 5~10번 정도 만든 후, 그 결괏값들의 평균을 사용하였다. (기본적으로 좋은 모델이란, 랜덤 성에 의한 성능의 편차가 작고, 일관성 있는 성능을 보이는 모델이 좋은 모델이라 할 수 있다. 모델의 평균적인 성능은 좋아도 그 편차가 크다면, 그 모델은 좋은 모델이라 할 수 없다고 생각한다)
여기서 흥미로운 점은, 앞서 언급했는데, 30일 예측에 있어 3가지 유형의 모델을 구축했다고 언급했었다. 회귀/분배/딥러닝 계열 모델로써, 이 3가지 모델을 구축하였고, 그 성능은 큰 차이는 없지만 딥러닝, 분배, 회귀 모델 순으로 우수한 성능을 보였다. 다만, 여기서 이 3가지 모델의 결과를 앙상블 하여(Stack Ensemble 같은 앙상블 모델을 구축하지도 않고, 단순히 결괏값들의 평균을 주었다) 그 예측 결과를 평가하였는데, 그 성능이 MAPE기준 20 이하까지도 향상되었다. 저유소와 유종에 따라 그 향상도가 다르긴 하지만 대체적으로 기존 단일 모델 성능 대비 약 30%가량의 성능 향상을 보였다.(이때, 별 기대 안 했는데 굉장히 놀랬었다)
결론적으로, 프로젝트가 끝났음에도 해당 과제의 목표(MAPE 15)를 달성하지 못하여, 기존 모델의 성능을 향상하기 위한 추가 모델링을 진행하였다. 사용할 수 있는 데이터는 현재 사용하고 있는 데이터에서 더 추가되지 못하고(요청정보가 존재하지 않거나, 사용할 수 없음) 모델 관점에서 개선을 할 필요가 있었다.
이러한 상황에서 생각한 아이디어로, 사용 가능한 미래 데이터를 추가 모델에 반영해주는 방법을 고안하였다.(다 끝나고 보니 시계열 Sota알고리즘이 이런 방식이었던... 왜 예전에 못 찾았는지;;)
해당 방법을 간략하게 설명하자면, 시계열 모델에서 사용할 수 있는 정보와 사용할 수 없는 정보를 가지고 있다. 예측시점 기준 미래 30일을 예측하는데, 미래 30일에 대한 온도나 날씨, 주가와 같은 정보들은 사용할 수 없는 정보들이다.(다만, 완전히 못쓰는 것은 아니다. 이러한 정보들을 사용하기 위해, 비록 다소 부정확하지만 이러한 속성 자체를 예측하는 모델을 만들어서 반영할 수도 있다) 다만, 이러한 정보들은 예측시점 기준 과거의 정보들은 사용할 수 있는데, 기존의 GRU모델이 예측시점 기준 5일 동한의 과거 정보들만을 가지고 학습할 수 있는 모델을 구축한 예이다. 다만, 우리가 예측하고자 하는 미래 30일 동안의 사용 가능한 정보들이 있는데, 해당 날짜의 직접적인 날짜 정보들(30일 동안의 날짜 정보, 요일 정보, 휴일 여부)과 해당 날짜의 과거 정보(예측시점 기준 미래 30일에 해당하는 1년/2년/3년... 전의 해당 날짜의 출하량과 같은 정보들)를 사용할 수 있는 정보들이다. 다만, 기존의 모델로 이러한 정보를 반영하기는 어렵기 때문에, 이러한 정보들을 입력으로 받고 학습할 수 있도록 모델을 재설계할 필요가 있었다.
이를 위해서 2가지 데이터셋을 구축하였다. 첫 번째 데이터셋은 기존의 예측시점 기준 과거 5일을 반영하고, 두 번째 데이터셋은 예측시점 기준 미래 30일을 반영하는 데이터셋을 구축하였다. 각각의 데이터는 2개의 GRU레이어에 병렬로 입력이 되며, 마지막에 DNN레이어에서 하나의 레이어로 합쳐지게 되고 30일 출하 예측값이 나오도록 모델 구조를 설계하였다. 그 과정과 구조는 아래와 같다.
이렇게 구축한 결과, 기존 모델 대비 모델은 무거워졌지만(학습 서버에서 안 돌아간다 이건), 성능은 MAPE기준 약 4프로가량 향상되었다(그래도 목표치엔 도달하지 못한다)
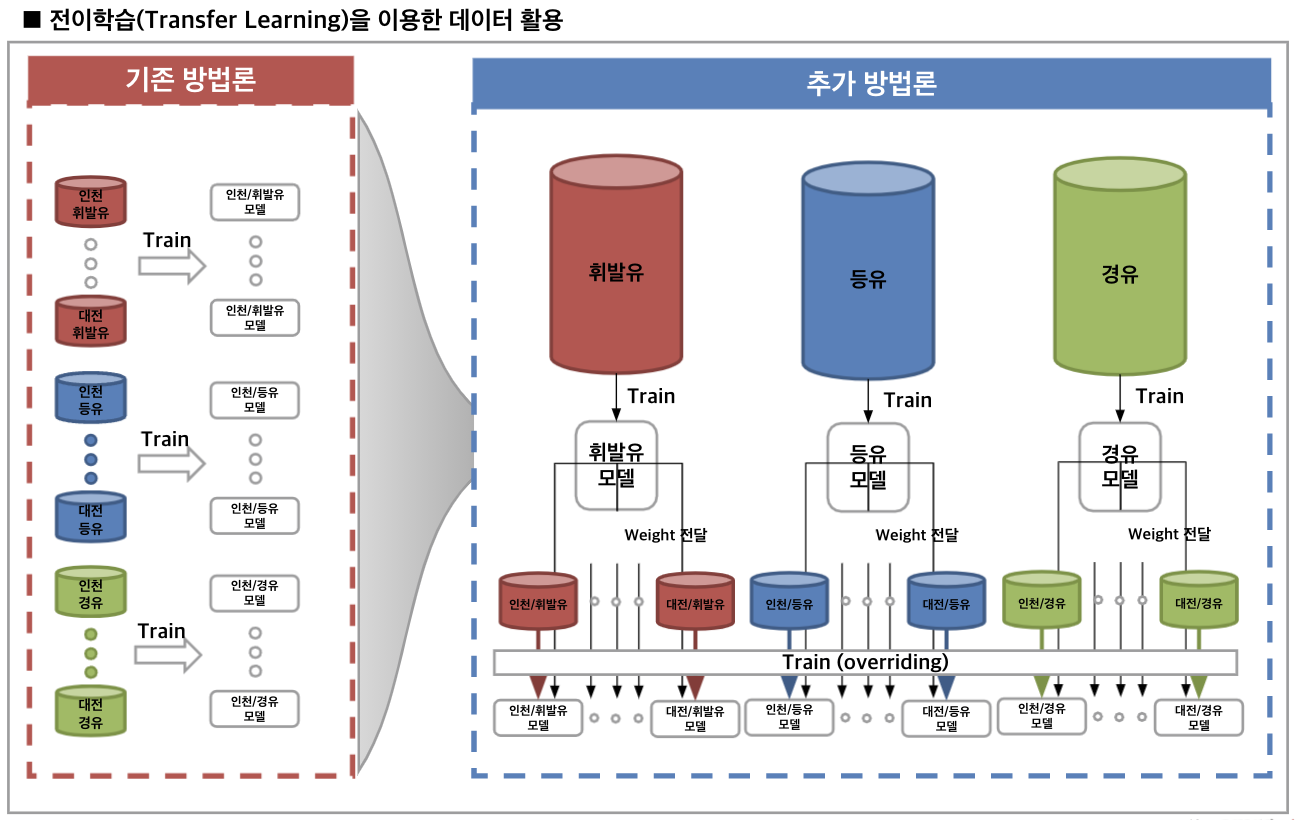
현재까지의 진행사항은 여기까지이며, 모델 성능 향상을 위해 진행해볼 계획은 첫 번째로, 시계열 모델의 Sota모델 구축(Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting, 2019년에 Google Cloud와 옥스퍼드대학에서 만든 Transformer를 사용한 시계열 모델이다) 및 검증을 진행해볼 계획이다. 두 번째로는 Transfer Learning 적용으로 이렇게 2가지 방법을 시도해볼 계획이다.
현재 모델에서 사용하는 데이터의 수는 약 6~7년간의 daily 데이터이기 때문에 약 2000개가량의 데이터만 존재한다. 이는 딥러닝에 있어서 굉장히 적은 수로, 다양한 패턴을 학습하기엔 굉장히 적은 수라고 추정된다. 다만, 우리는 저유소별(13개 저유소)로 데이터가 각각 약 2000개씩 존재하기 때문에, 타 저유소의 정보를 Transfer Learning을 이용하여 학습한다면, 데이터 부족을 어느 정도 해소할 수 있을 것이라 추정한다.(다만, 저유소별로 개별 특징이 있고 이러한 점이 데이터에 반영되어 있기 때문에, 처음부터 데이터를 통합하여 모델 학습에 사용하면 오히려 성능이 더 떨어진다)